

hapFabia: Software for identification of very short segments of identity by descent (IBD) characterized by rare variants in large sequencing data
hapFabia is an R package for identification of very short segments of identity by descent (IBD) characterized by rare variants in large sequencing data. hapFabia is also available at bioconductor hapFabia.
Summary
Our software package hapFabia identifies short identity by descent (IBD) segments that are tagged by rare variants in large sequencing data. Two haplotypes are identical by descent (IBD) if they share a segment that both inherited from a common ancestor. Current IBD methods reliably detect long IBD segments because many minor alleles in the segment are concordant between the two haplotypes. However, many cohort studies contain unrelated individuals which share only short IBD segments. Short IBD segments contain too few minor alleles to distinguish IBD from random allele sharing by recurrent mutations. New sequencing techniques improve the situation by providing rare variants which convey more information on IBD than common variants, because random minor allele sharing of rare variants is less likely than for common variants.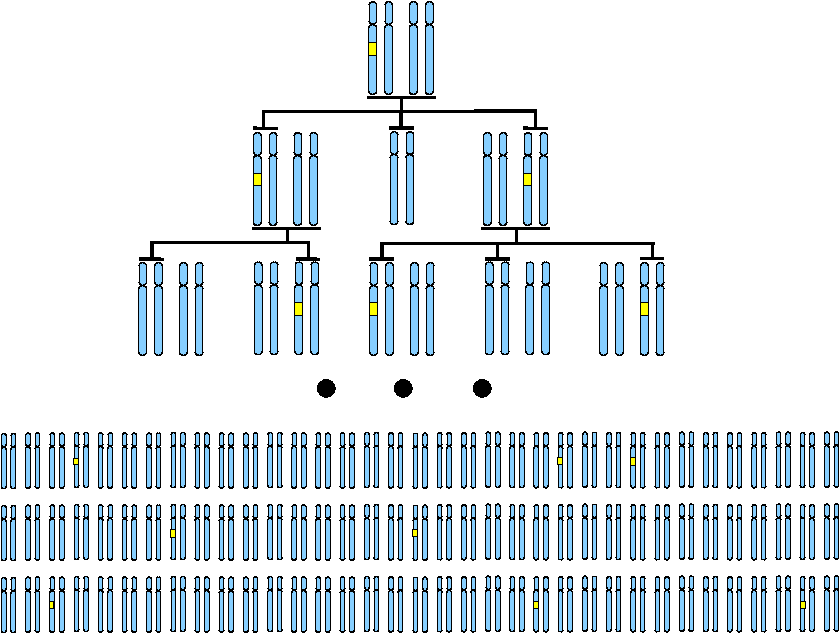 IBD segment (yellow) that descended from a founder to different individuals. |
Short IBD segments are of interest because (i) they resolve the genetic structure on a fine scale and (ii) they can be assumed to be old. In order to detect short IBD segments, both the information supplied by rare variants and information from more than two individuals should be utilized. These two characteristics are the basis for detecting short IBD segments by HapFABIA. We propose biclustering to detect very short IBD segments that are shared among multiple individuals. Biclustering simultaneously clusters rows and columns of a matrix. In particular it clusters row elements that are similar to each other on a subset of column elements. A genotype matrix has individuals (unphased) or chromosomes (phased) as row elements and SNVs as column elements. Entries in the genotype matrix usually count how often the minor allele of a particular SNV is present in a particular individual. Alternatively, minor allele likelihoods or dosages may be used. Individuals that share an IBD segment are similar to each other at minor alleles of SNVs (tagSNVs) which tag the IBD segment (see Figure below). Therefore an IBD segment that is shared among individuals corresponds to a bicluster because these individuals are similar to one another at this segment. Identifying a bicluster means identifying tagSNVs (column bicluster elements) that tag an IBD segment and, simultaneously, identifying individuals (row bicluster elements) that possess the IBD segment.
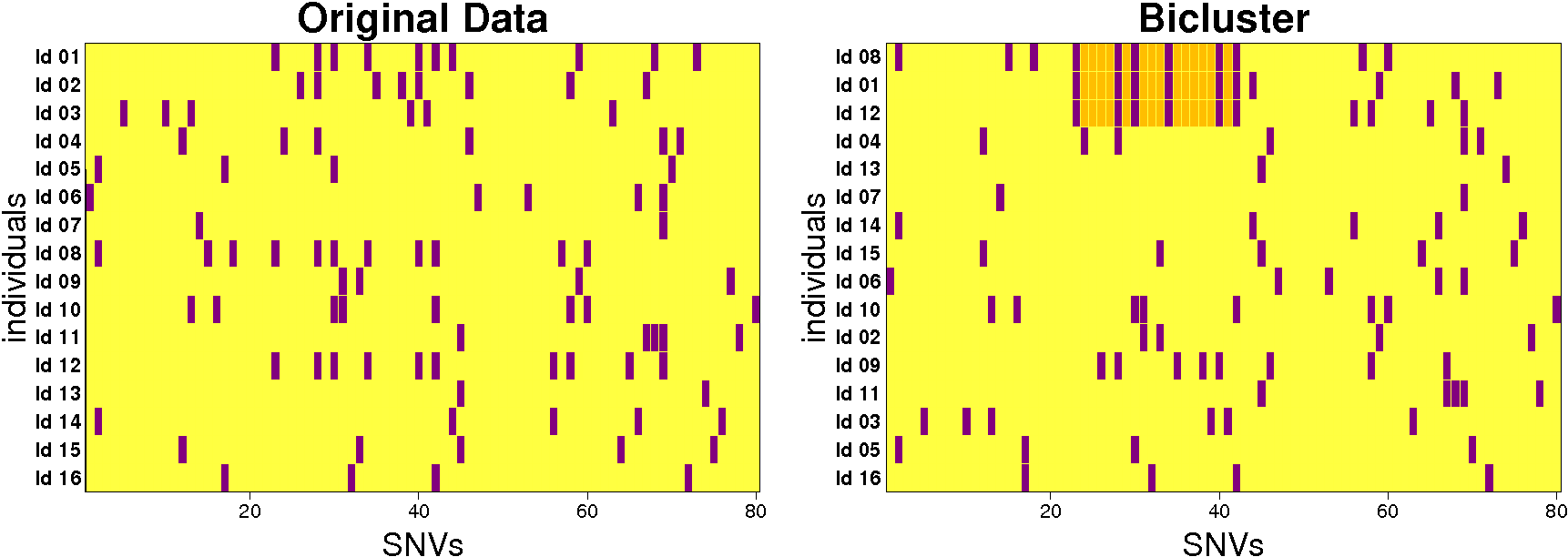 Biclustering of a genotyping matrix. Left: original genotyping data matrix with individuals as row elements and SNVs as column elements. Minor alleles are indicated by violet bars and major alleles by yellow bars for each individual-SNV pair. Right: after sorting the rows, the detected bicluster can be seen in the top three individuals. They contain the same IBD segment which is marked in gold. Biclustering simultaneously clusters rows and columns of a matrix so that row elements (here individuals) are similar to each other on a subset of column elements (here the tagSNVs). |
Publication
- Abstract:
Abstract
- Full:
Full Text
- Supplementary Information:
supplemental information
Research Report: IBD between Humans, Neandertals, and Denisovans
Software, Data, Source Codes
- Software:
HapFabia devel:
hapFabia_1.17.1.tar.gz (R 3.4.0, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.17.1.tgz (R 3.4.0, 1.7M, MAC 10.9.5, ## with fabia >= 2.3.1! ## )
hapFabia_1.17.1.zip (R 3.4.0, 3.4M, Windows 32/64, ## with fabia >= 2.3.1! ## )
HapFabia:
hapFabia_1.16.1.tar.gz (R 3.3.3, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.16.1.tgz (R 3.3.3, 1.7M, MAC 10.9.5, ## with fabia >= 2.3.1! ## )
hapFabia_1.16.1.zip (R 3.3.3, 3.4M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.15.0.tar.gz (R 3.3.1, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.15.0.tgz (R 3.3.1, 1.7M, MAC 10.9.5, ## with fabia >= 2.3.1! ## )
hapFabia_1.15.0.zip (R 3.3.1, 3.4M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.14.0.tar.gz (R 3.3.1, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.14.0.tgz (R 3.3.1, 1.7M, MAC 10.9.5, ## with fabia >= 2.3.1! ## )
hapFabia_1.14.0.zip (R 3.3.1, 3.4M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.13.0.tar.gz (R 3.2.2, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.13.0.tgz (R 3.2.2, 1.7M, MAC 10.9, ## with fabia >= 2.3.1! ## )
hapFabia_1.13.0.zip (R 3.2.2, 3.4M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.12.0.tar.gz (R 3.2.2, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.12.0.tgz (R 3.2.2, 1.7M, MAC 10.9, ## with fabia >= 2.3.1! ## )
hapFabia_1.12.0.zip (R 3.2.2, 3.4M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.11.0.tar.gz (R 3.2.0, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.11.0.tgz (R 3.2.0, 1.7M, MAC 10.9, ## with fabia >= 2.3.1! ## )
hapFabia_1.11.0.tgz (R 3.2.0, 1.7M, MAC 10.6, ## with fabia >= 2.3.1! ## )
hapFabia_1.11.0.zip (R 3.2.0, 3.4M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.10.0.tar.gz (R 3.2.0, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.10.0.tgz (R 3.2.0, 1.7M, MAC 10.9, ## with fabia >= 2.3.1! ## )
hapFabia10.6_1.10.0.tgz (R 3.2.0, 1.7M, MAC 10.6, ## with fabia >= 2.3.1! ## )
hapFabia_1.10.0.zip (R 3.2.0, 3.4M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.9.0.tar.gz (R 3.1.1, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.9.0.tgz (R 3.1.1, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.9.0.zip (R 3.1.1, 3.2M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.8.0.tar.gz (R 3.1.1, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.8.0.tgz (R 3.1.1, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.8.0.zip (R 3.1.1, 3.2M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.7.4.tar.gz (R 3.1.0, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.7.4.tgz (R 3.1.0, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.7.4.zip (R 3.1.0, 3.2M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.6.3.tar.gz (R 3.1.0, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.6.3.tgz (R 3.1.0, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.6.3.zip (R 3.1.0, 3.2M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.6.2.tar.gz (R 3.1.0, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.6.2.tgz (R 3.1.0, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.6.2.zip (R 3.1.0, 3.2M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.6.1.tar.gz (R 3.1.0, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.6.1.zip (R 3.1.0, 3.2M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.6.0.tar.gz (R 3.1.0, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.6.0.tgz (R 3.1.0, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.6.0.zip (R 3.1.0, 3.2M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.5.2.tar.gz (R 3.0.2, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.5.2.tgz (R 3.0.2, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.5.2.zip (R 3.0.2, 1.6M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.4.2.tar.gz (R 3.0.2, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.4.2.tgz (R 3.0.2, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.4.2.zip (R 3.0.2, 1.6M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.4.1.tar.gz (R 3.0.1, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.4.1.tgz (R 3.0.1, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.4.1.zip (R 3.0.1, 1.6M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.4.0.tar.gz (R 3.0.1, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.4.0.tgz (R 3.0.1, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.4.0.zip (R 3.0.1, 1.6M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.3.2.tar.gz (R 3.0.0, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.3.2.tgz (R 3.0.0, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.3.2.zip (R 3.0.0, 1.6M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.2.2.tar.gz (R 3.0.0, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.2.2.tgz (R 3.0.0, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.2.2.zip (R 3.0.0, 1.6M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.2.1.tar.gz (R 3.0.0, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.2.1.tgz (R 3.0.0, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.2.1.zip (R 3.0.0, 1.6M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.2.0.tar.gz (R 3.0.0, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.2.0.tgz (R 3.0.0, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.2.0.zip (R 3.0.0, 1.6M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.1.6.tar.gz (R 2.15.2, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.1.6.zip (R 2.15.2, 1.7M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.6.tar.gz (R 2.15.2, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.6.zip (R 2.15.2, 1.7M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.5.tar.gz (R 2.15.2, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.5.zip (R 2.15.2, 1.7M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.4.tar.gz (R 2.15.2, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.4.tgz (R 2.15.2, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.4.zip (R 2.15.2, 1.6M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.3.tar.gz (R 2.15.1, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.3.tgz (R 2.15.1, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.3.zip (R 2.15.1, 1.6M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.2.tar.gz (R 2.15.1, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.2.tgz (R 2.15.1, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.2.zip (R 2.15.1, 1.6M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.1.tar.gz (R 2.15.1, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.1.zip (R 2.15.1, 1.6M, Windows 32, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.0.tar.gz (R 2.15.1, 1.6M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.0.tgz (R 2.15.1, 1.6M, MAC, ## with fabia >= 2.3.1! ## )
hapFabia_1.0.0.zip (R 2.15.1, 1.6M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_0.99.1.tar.gz (R 2.15.1, 1.5M, UNIX, ## with fabia >= 2.3.1! ## )
hapFabia_0.99.1.zip (R 2.15.1, 1.7M, Windows 32/64, ## with fabia >= 2.3.1! ## )
hapFabia_0.99.1.tgz (R 2.15.1, 1.7M, MAC, ## with fabia >= 2.3.1! ##)
hapFabia_0.90.0.tar.gz (R 2.15.0, 1.0M, UNIX, ## with fabia <= 2.3.0! ## )
hapFabia_0.90.0.zip (R 2.15.0, 400k, Windows 32, ## with fabia <= 2.3.0! ## )
hapFabia_0.90.0.tar.gz (R 2.14.1, 1.0M, UNIX, ## with fabia <= 2.3.0! ## )
hapFabia_0.90.0.zip (R 2.14.0, 400k, Windows, ## with fabia <= 2.3.0! ## )
Fabia:
fabia_2.21.0.tar.gz (R 3.4.0, 780 kB, UNIX)
fabia_2.21.0.tgz (R 3.4.0, 940 kB, MAC 10.9.5)
fabia_2.21.0.zip (R 3.4.0, 1.9M, Windows 32/64)
fabia_2.20.0.tar.gz (R 3.3.3, 780 kB, UNIX)
fabia_2.20.0.tgz (R 3.3.3, 940 kB, MAC 10.9.5)
fabia_2.20.0.zip (R 3.3.3, 1.9M, Windows 32/64)
fabia_2.19.0.tar.gz (R 3.3.1, 780 kB, UNIX)
fabia_2.19.0.tgz (R 3.3.1, 940 kB, MAC 10.9.5)
fabia_2.19.0.zip (R 3.3.1, 1.9M, Windows 32/64)
fabia_2.18.0.tar.gz (R 3.3.1, 780 kB, UNIX)
fabia_2.18.0.tgz (R 3.3.1, 940 kB, MAC 10.9.5)
fabia_2.18.0.zip (R 3.3.1, 1.9M, Windows 32/64)
fabia_2.17.0.tar.gz (R 3.2.2, 780 kB, UNIX)
fabia_2.17.0.tgz (R 3.2.2, 940 kB, MAC 10.9)
fabia_2.17.0.zip (R 3.2.2, 1.9M, Windows 32/64)
fabia_2.16.0.tar.gz (R 3.2.2, 780 kB, UNIX)
fabia_2.16.0.tgz (R 3.2.2, 940 kB, MAC 10.9)
fabia_2.16.0.zip (R 3.2.2, 1.9M, Windows 32/64)
fabia_2.15.0.tar.gz (R 3.2.0, 780 kB, UNIX)
fabia_2.15.0.tgz (R 3.2.0, 940 kB, MAC 10.9)
fabia10.6_2.15.0.tgz (R 3.2.0, 940 kB, MAC 10.6)
fabia_2.15.0.zip (R 3.2.0, 1.9M, Windows 32/64)
fabia_2.14.0.tar.gz (R 3.2.0, 780 kB, UNIX)
fabia_2.14.0.tgz (R 3.2.0, 940 kB, MAC 10.9)
fabia10.6_2.14.0.tgz (R 3.2.0, 940 kB, MAC 10.6)
fabia_2.14.0.zip (R 3.2.0, 1.9M, Windows 32/64)
fabia_2.13.0.tar.gz (R 3.1.1, 1.0M, UNIX)
fabia_2.13.0.tgz (R 3.1.1, 1.0M, MAC)
fabia_2.13.0.zip (R 3.1.1, 1.0M, Windows 32/64)
fabia_2.12.0.tar.gz (R 3.1.1, 1.0M, UNIX)
fabia_2.12.0.tgz (R 3.1.1, 1.0M, MAC)
fabia_2.12.0.zip (R 3.1.1, 1.0M, Windows 32/64)
fabia_2.11.2.tar.gz (R 3.1.0, 1.0M, UNIX)
fabia_2.11.2.tgz (R 3.1.0, 1.0M, MAC)
fabia_2.11.2.zip (R 3.1.0, 1.0M, Windows 32/64)
fabia_2.10.2.tar.gz (R 3.1.0, 1.0M, UNIX)
fabia_2.10.2.tgz (R 3.1.0, 1.0M, MAC)
fabia_2.10.2.zip (R 3.1.0, 1.0M, Windows 32/64)
fabia_2.10.1.tar.gz (R 3.1.0, 1.0M, UNIX)
fabia_2.10.1.tgz (R 3.1.0, 1.0M, MAC)
fabia_2.10.1.zip (R 3.1.0, 1.0M, Windows 32/64)
fabia_2.10.0.tar.gz (R 3.1.0, 1.0M, UNIX)
fabia_2.10.0.tgz (R 3.1.0, 1.0M, MAC)
fabia_2.10.0.zip (R 3.1.0, 1.0M, Windows 32/64)
fabia_2.9.0.tar.gz (R 3.0.1, 1.0M, UNIX)
fabia_2.9.0.tgz (R 3.0.1, 1.0M, MAC)
fabia_2.8.0.tar.gz (R 3.0.1, 1.0M, UNIX)
fabia_2.8.0.tgz (R 3.0.1, 1.0M, MAC)
fabia_2.8.0.zip (R 3.0.1, 1.0M, Windows 32/64)
fabia_2.7.1.tar.gz (R 3.0.0, 1.0M, UNIX)
fabia_2.7.1.tgz (R 3.0.0, 1.0M, MAC)
fabia_2.7.1.zip (R 3.0.0, 1.0M, Windows 32/64)
fabia_2.6.1.tar.gz (R 3.0.0, 1.0M, UNIX)
fabia_2.6.1.zip (R 3.0.0, 1.0M, Windows 32/64)
fabia_2.6.1.tgz (R 3.0.0, 1.0M, MAC)
fabia_2.6.0.tar.gz (R 3.0.0, 1.0M, UNIX)
fabia_2.6.0.zip (R 3.0.0, 1.0M, Windows 32/64)
fabia_2.6.0.tgz (R 3.0.0, 1.0M, MAC)
fabia_2.4.0.tar.gz (R 2.15.1, 1.0M, UNIX)
fabia_2.4.0.zip (R 2.15.1, 1.0M, Windows 32/64)
fabia_2.4.0.tgz (R 2.15.1, 1.0M, MAC)
fabia_2.3.1.tar.gz (R 2.15.1, 1.0M, UNIX)
fabia_2.3.1.zip (R 2.15.1, 1.0M, Windows 32/64)
fabia_2.3.1.tgz (R 2.15.1, 1.0M, MAC)
fabia_2.3.0.tar.gz (R 2.15.0, 1.0M, UNIX)
fabia_2.3.0.zip (R 2.15.0, 1.0M, Windows 32/64)
fabia_2.2.2.tar.gz (R 2.15.0, 1.0M, UNIX)
fabia_2.2.2.zip (R 2.15.0, 1.0M, Windows 32/64)
fabia_2.2.0.tar.gz (R 2.15.0, 1.0M, UNIX)
fabia_2.2.0.tgz (R 2.15.0, 1.0M, MAC)
fabia_2.2.0.zip (R 2.15.0, 1.0M, Windows 32/64)
- Data, results, source code, scripts used in the analysis - used hapFabia
0.90.0:
Data, results, source code, scripts
Examples of Short IBD Segments in Chromosome 1 of the 1000 Genomes Project
Figures 1-6: Examples of IBD segments that were extracted from chromosome 1 of the 1000 Genomes Project. For these phased genotype data, phasing errors can be seen (yellow lines from the left hand side). Click on any of these thumbnails to view full-size images.
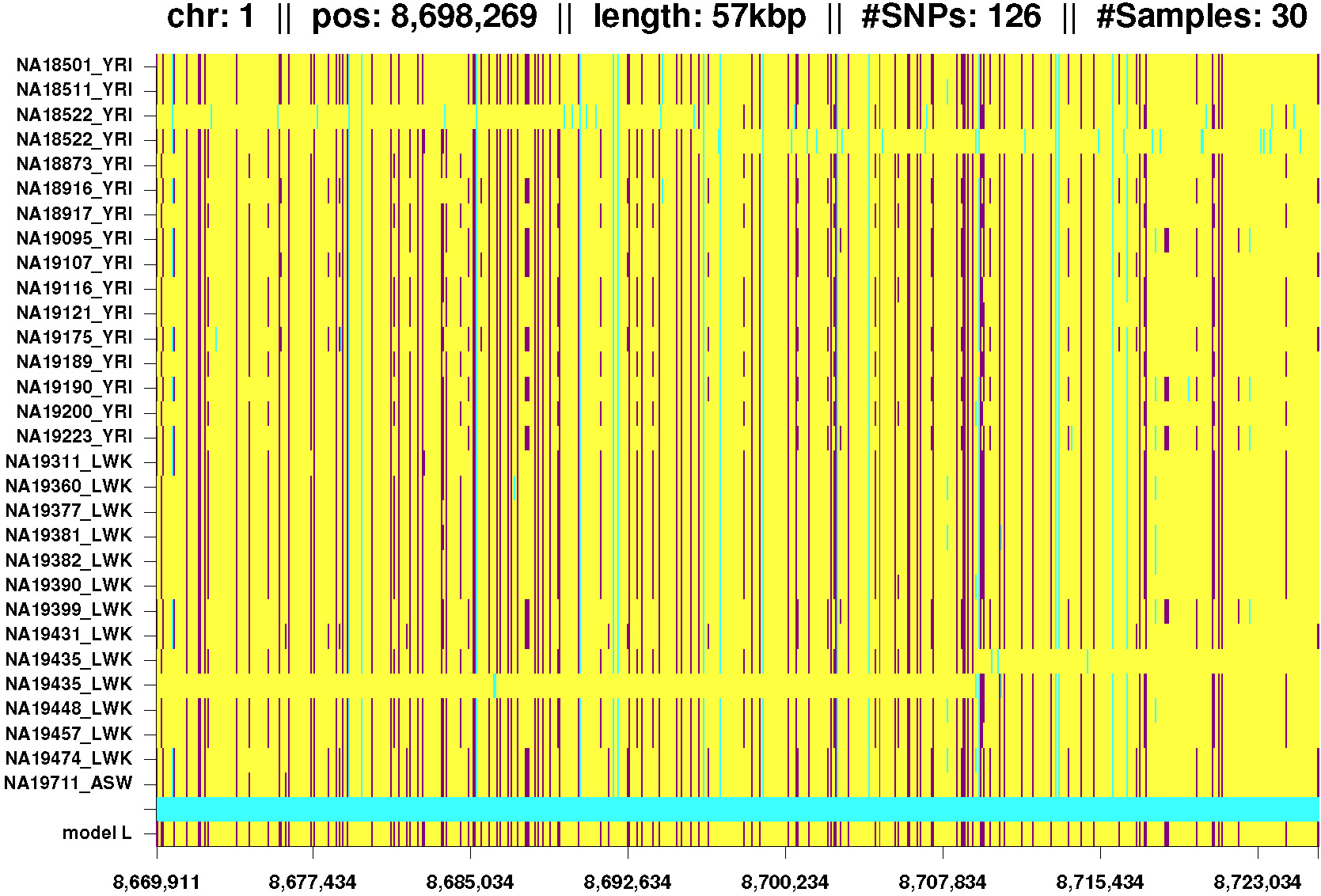 Fig. 1: IBD segment exclusively found in Africans. The third and fourth line very likely show a phasing error as both chromosomes belong to the same individual. Analog the last but fourth and last but fifth line. |
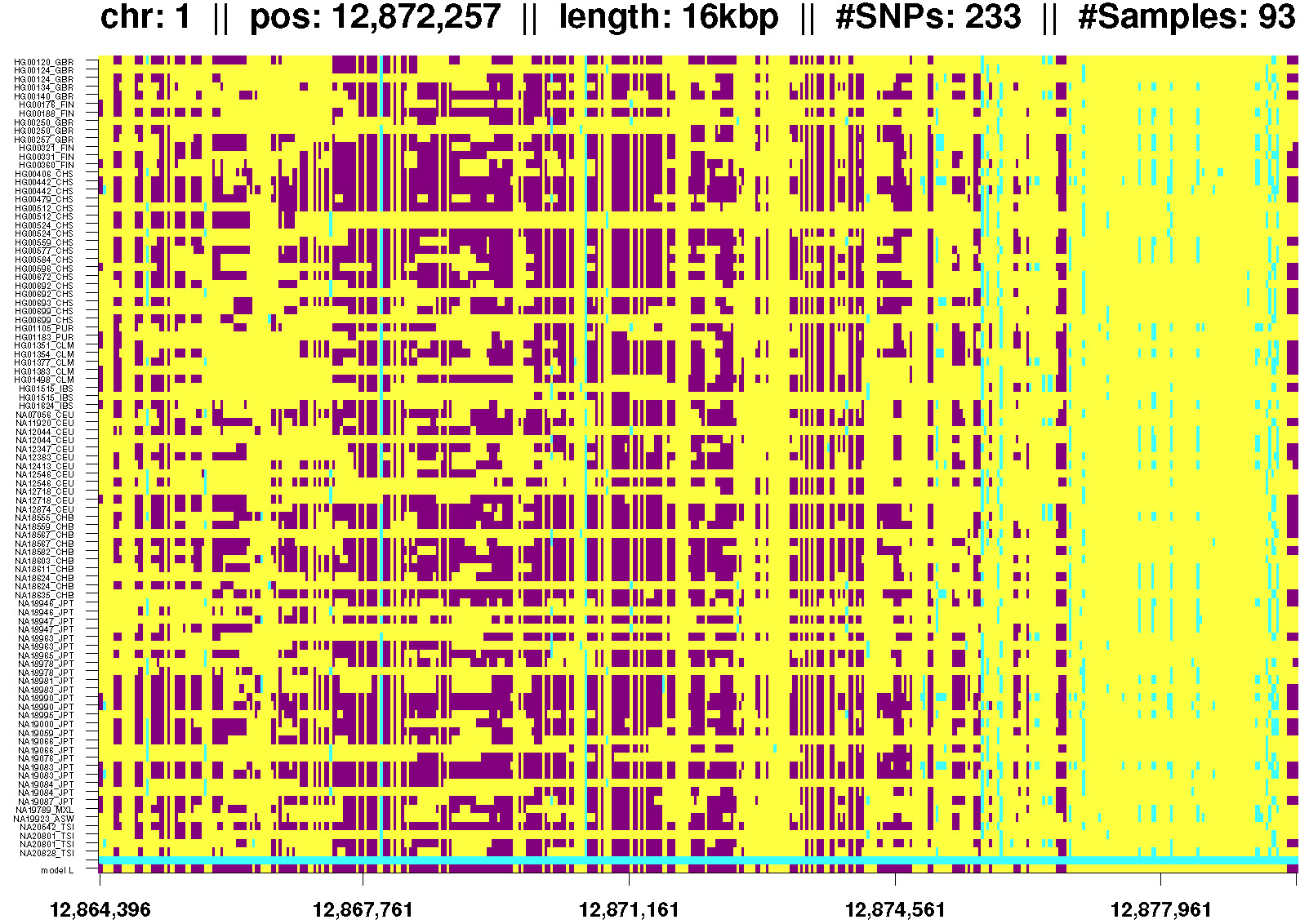 Fig. 2: IBD segment observed in all populations including one African. However this might also be a region of sequencing errors because the tagSNV pattern is not very clear. |
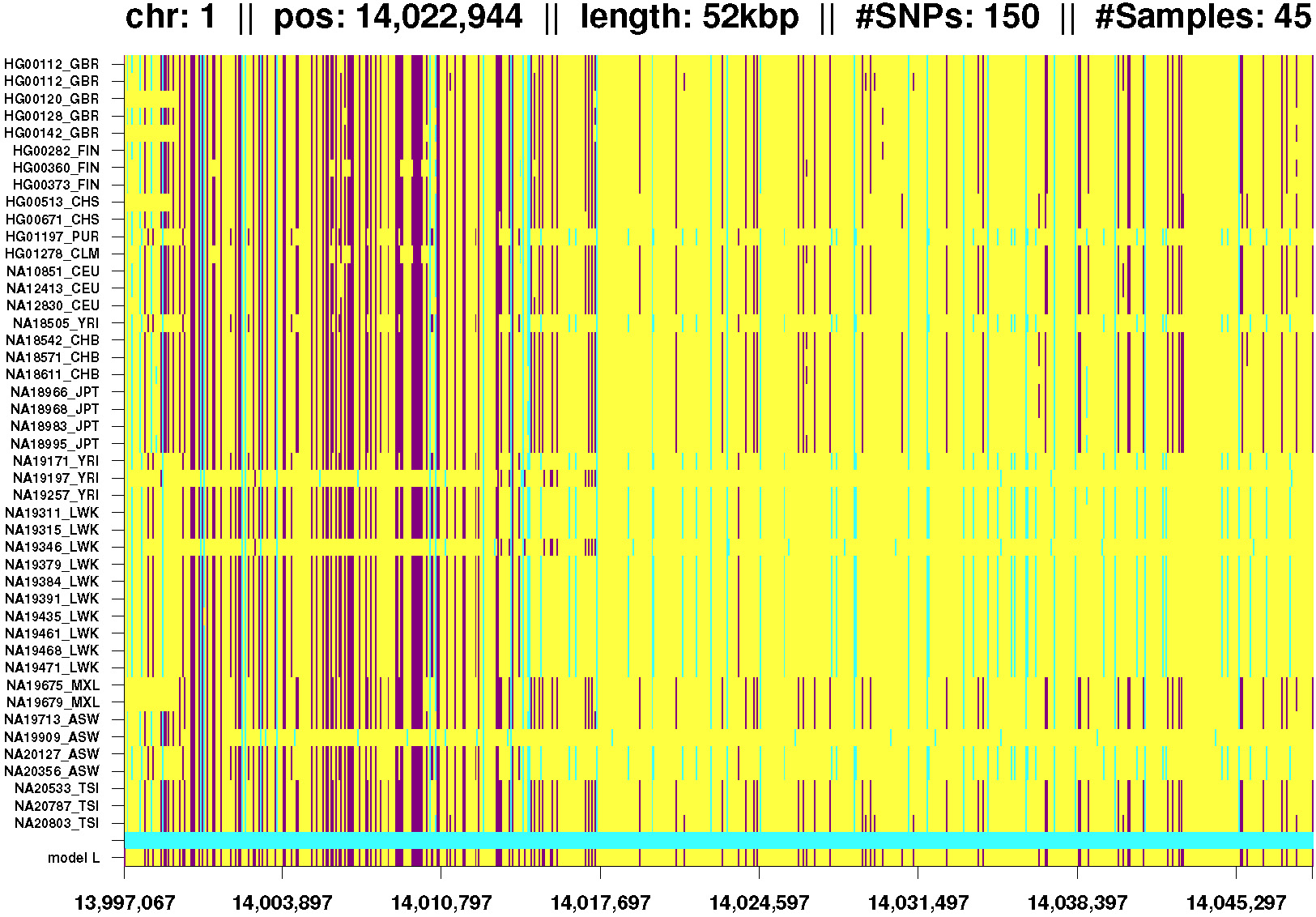 Fig. 3: IBD segment observed in all populations. |
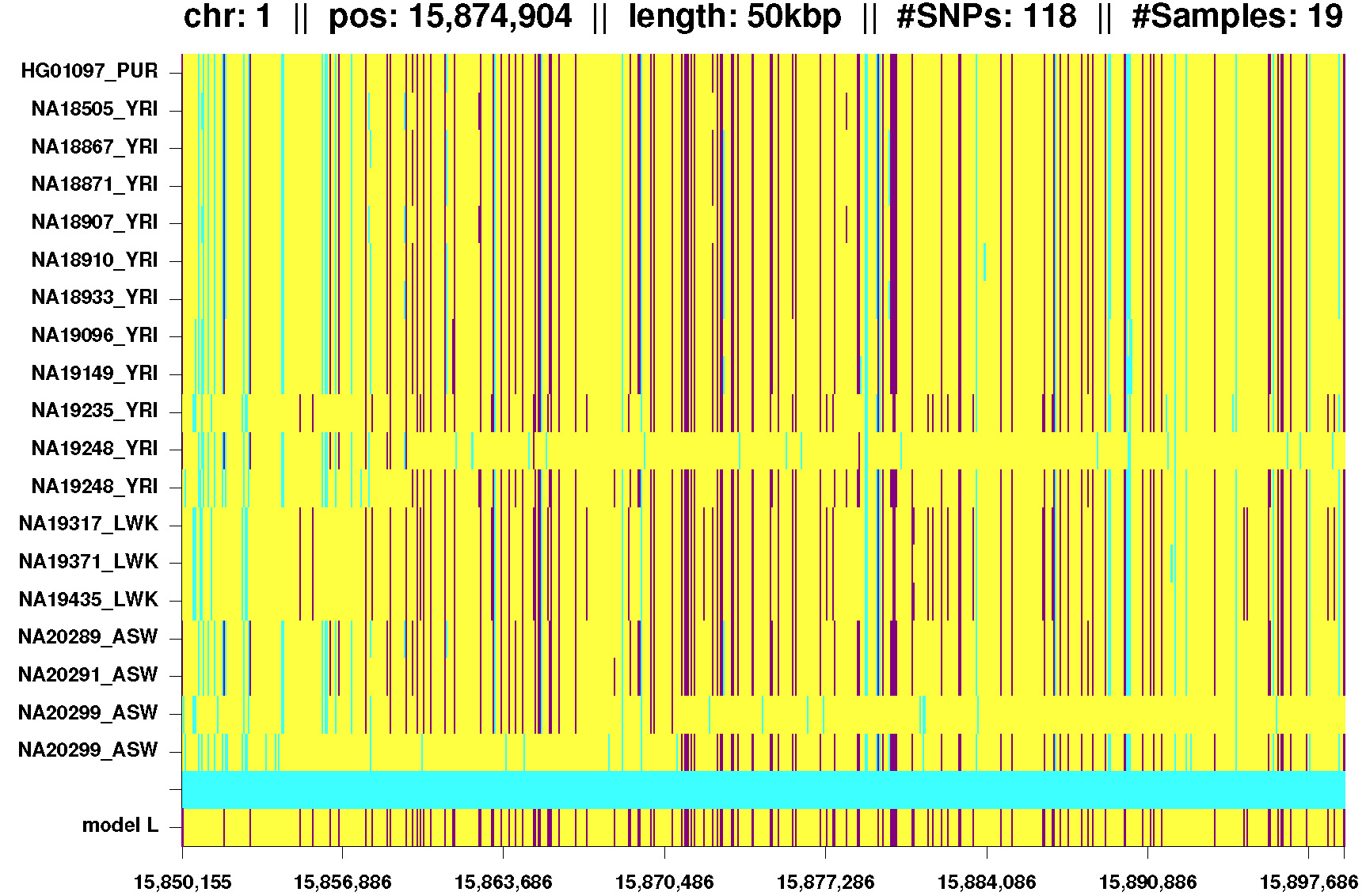 Fig. 4: IBD segment shared by Africans and one admixed American. Again phasing errors for the last two lines (NA20299) and lines 11 and 12 (NA19248). |
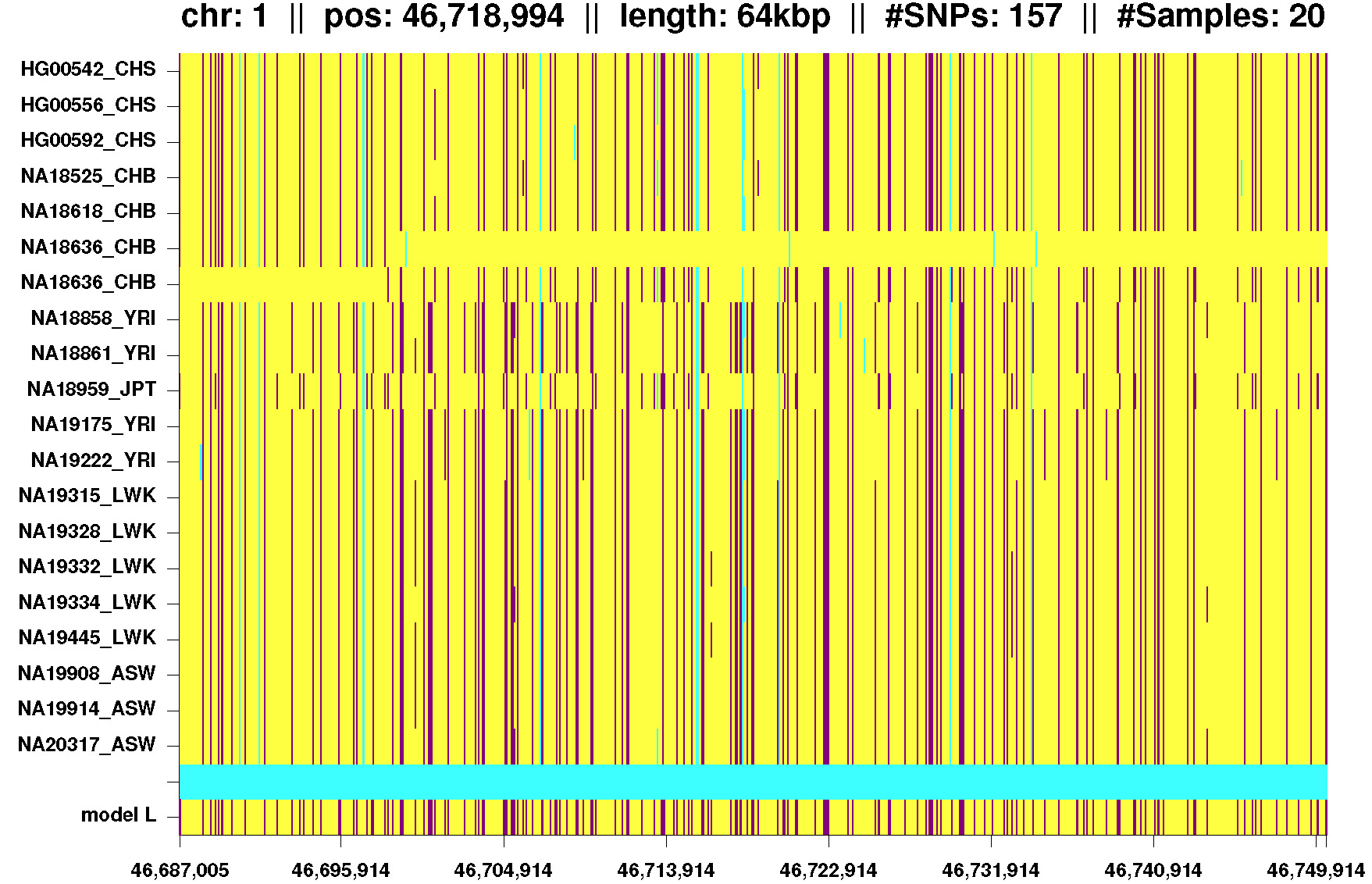 Fig. 5: IBD segment shared by Africans and Asians. Phasing errors at lines 6 and 7 (NA18636). |
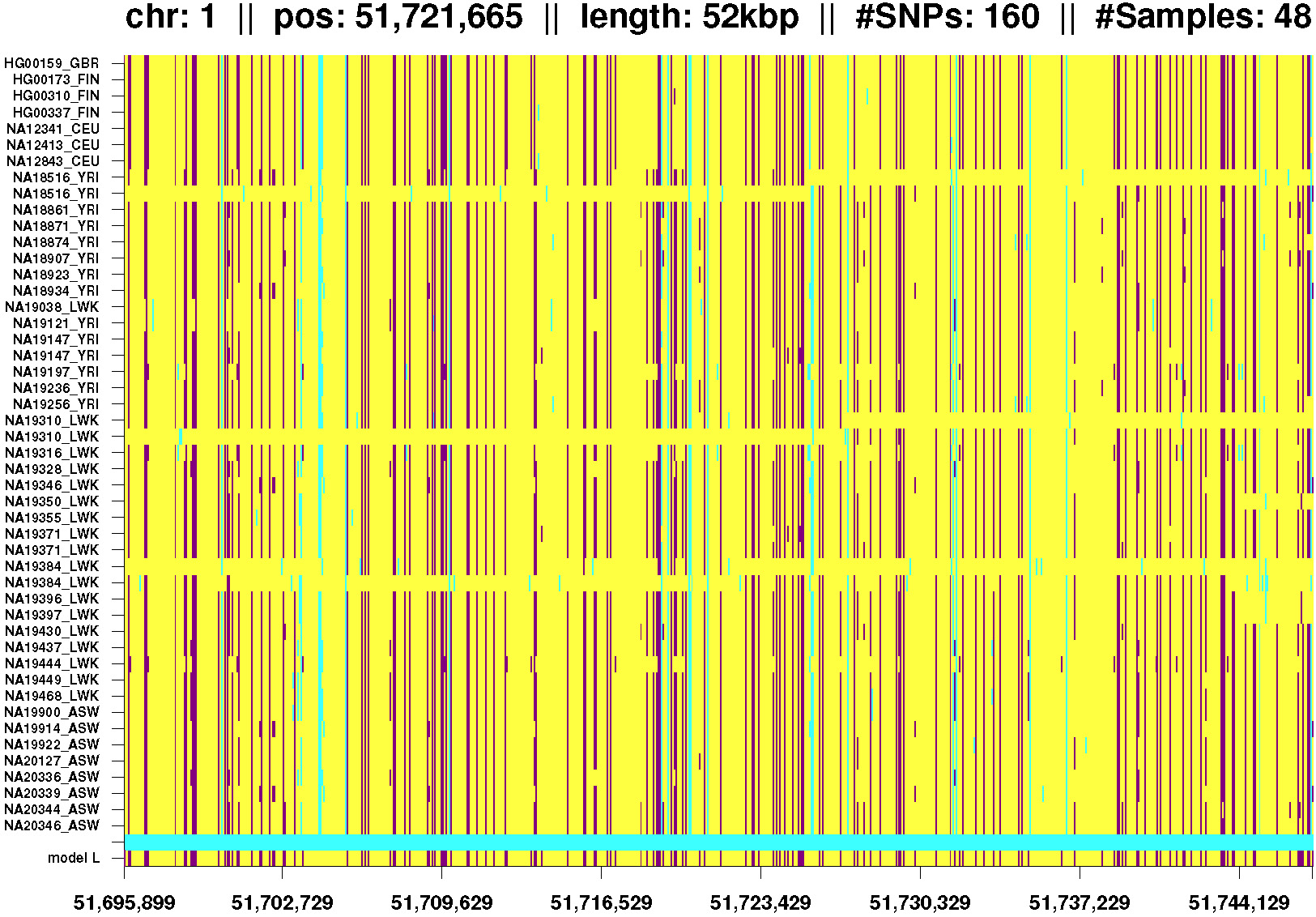 Fig. 6: IBD segment shared by Africans and Europeans. Phasing errors at lines 8 and 9 (NA18516), lines 23 and 24 (NA19310), and lines 32 and 33 (NA19384). |
Short IBD Segments Found in Data from the Korean Personal Genome Project (KPGP)
The Korean Personal Genome Project (KPGP) is part of the international Personal Genome Project (PGP) established by Genome Research Foundation (GRF). 39 Human genomes were sequenced on an Illumina HiSeq 2000 platform with 30x to 40x coverage. The genotypes of these 38 Koreans and one Caucasian female are combined with the genotype data of the 1000 Genomes Project to extract short IBD segments by HapFABIA.Data/results of hapFabia IBD segment extraction on the KPGP data - used hapFabia 0.90.0:
Data, results, and KPGP IBD segments
The KPGP data contains two twin pairs (KPGP88/KPGP89 and KPGP90/KPGP91) and a family (KPGP1-KPGP12). KPGP10 is a Caucasian female from US. The relations are given in the following pedigree charts:
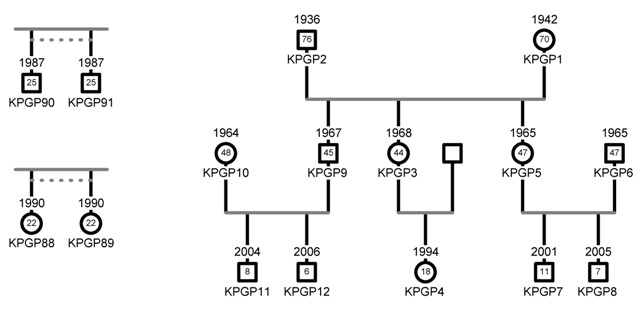 Pedigree charts for the KPGP individuals. Click on thumbnail to view full-size image. |
Figures K1-K7: Examples of short IBD segments from
chromosome 1 of the KPGP combined with the 1000 Genomes Project. Click on any of these thumbnails to view full-size images.
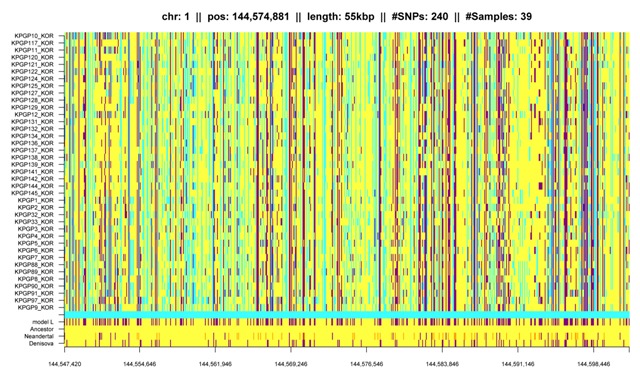 Fig. K1: IBD segment caused by systematic sequencing errors. Note that this segment is observed in all KPGP individuals and only those, though KPGP10 is a Caucasian female. |
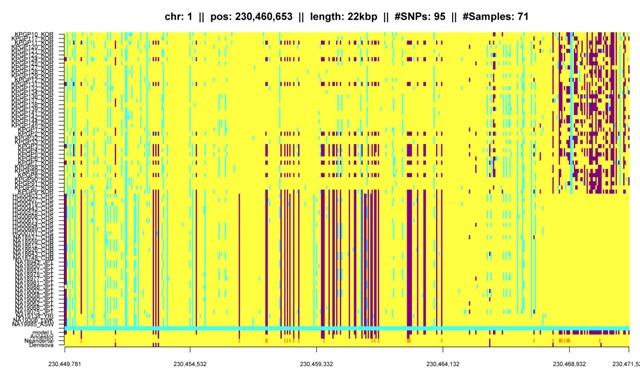 Fig. K2: IBD segment with sequencing errors for KPGP individuals at the right hand side. Some Koreans are classified to have this segment because they only agree to other Koreans at the sequencing errors. |
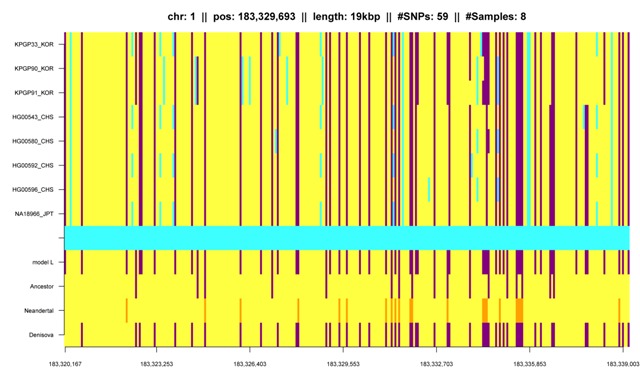 Fig. K3: IBD segment that matches the Denisova genome and shared among Asians, in particular Koreans. |
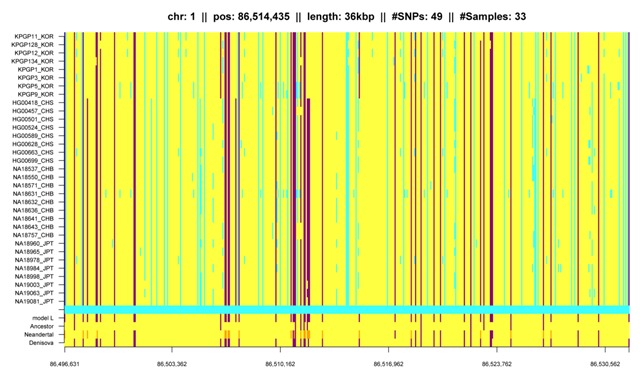 Fig. K4: Another IBD segment that matches the Denisova genome and is shared by Asians, in particular observed in Koreans. |
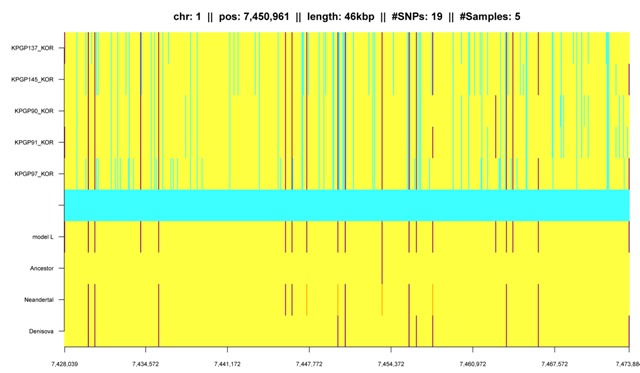 Fig. K5: IBD segment exclusively shared by Koreans. |
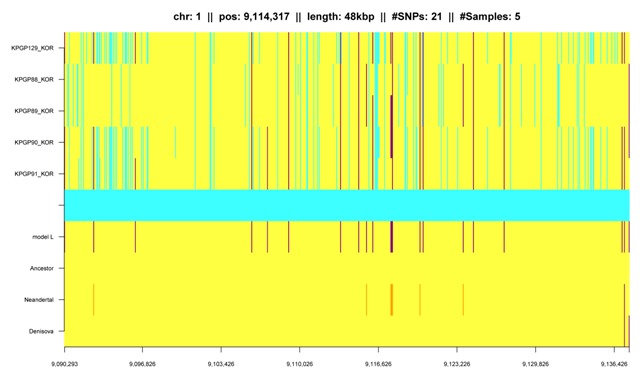 Fig. K6: IBD segment that is shared by both Korean twin pairs. Sequencing errors can be seen as twins should have the same IBD segments. |
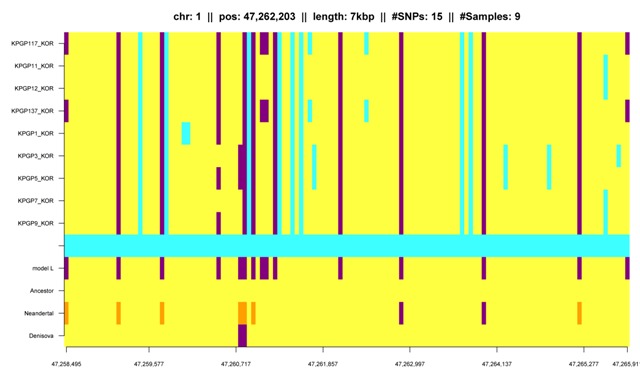 Fig. K7: IBD segment which is shared by many members of the Korean family. The IBD segment is descended from KPGP1 to all her children (KPGP3, KPGP5, KPGP9) and some of her grandchildren (KPGP7, KPGP11, KPGP12). |
Correlation between population proportions and ancient genomes based on short IBD segments
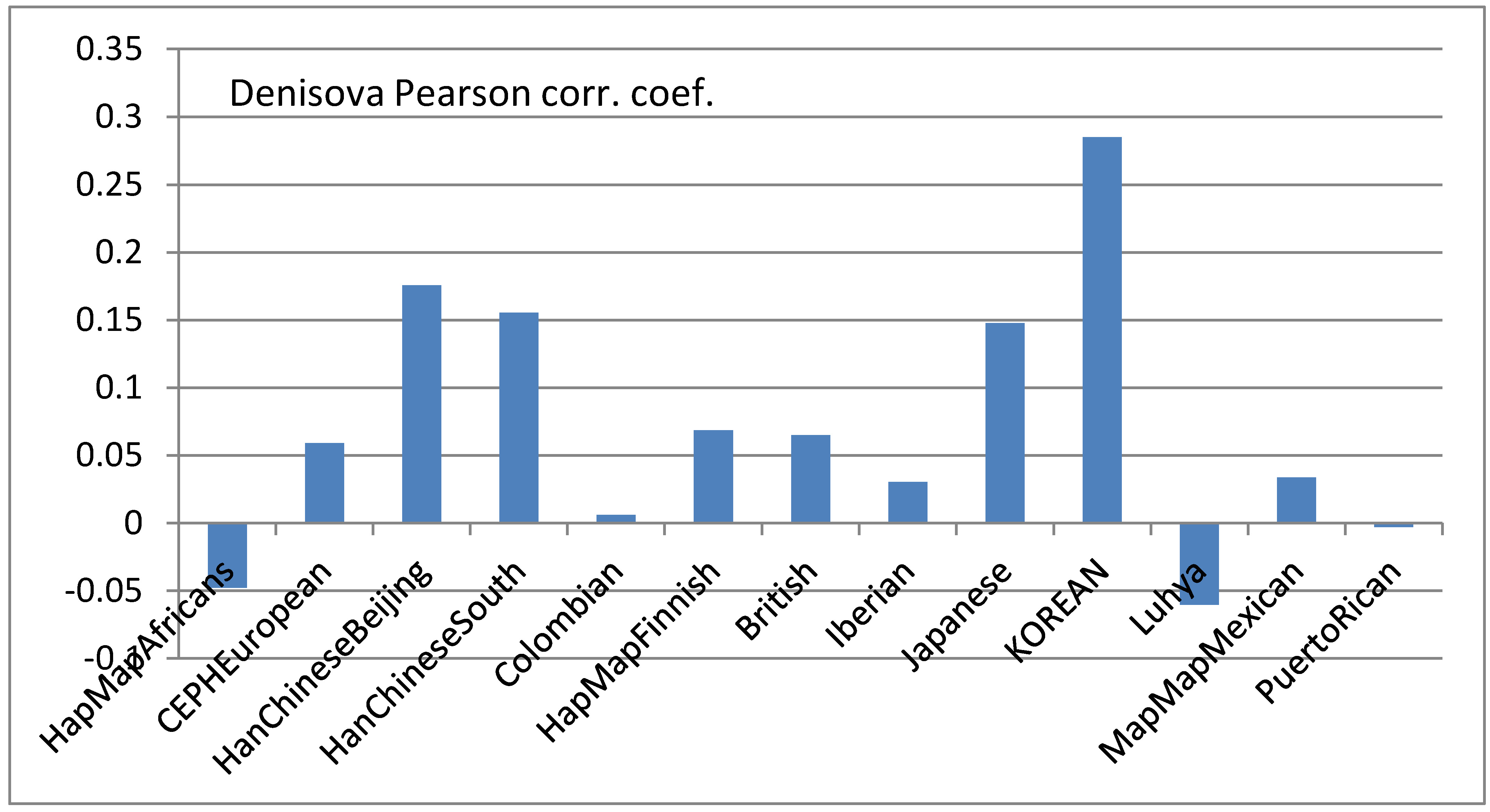 Persons correlation between the Denisova genome and different populations. |
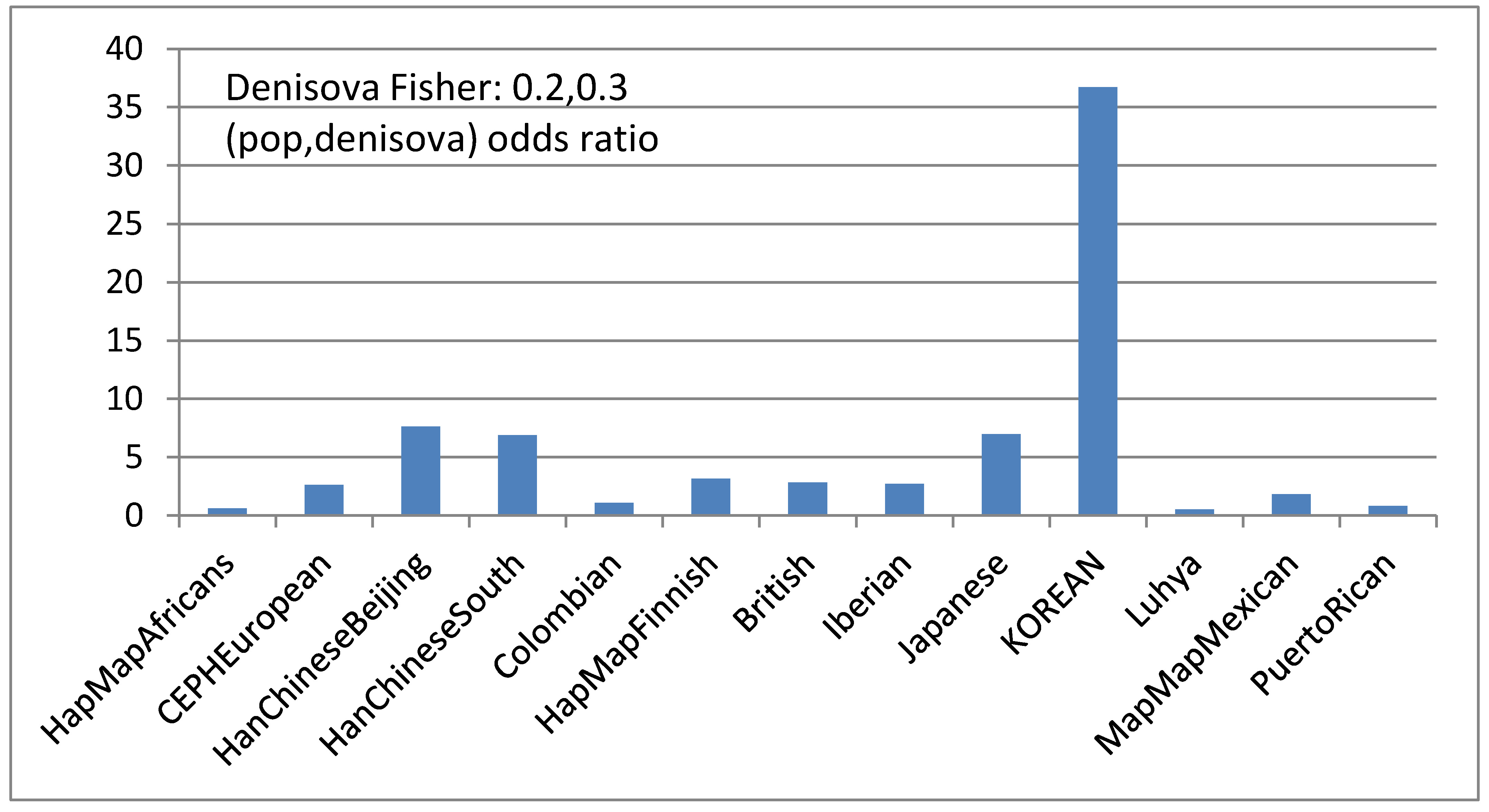 Fisher test for dependencies between the Denisova genome and different populations. |
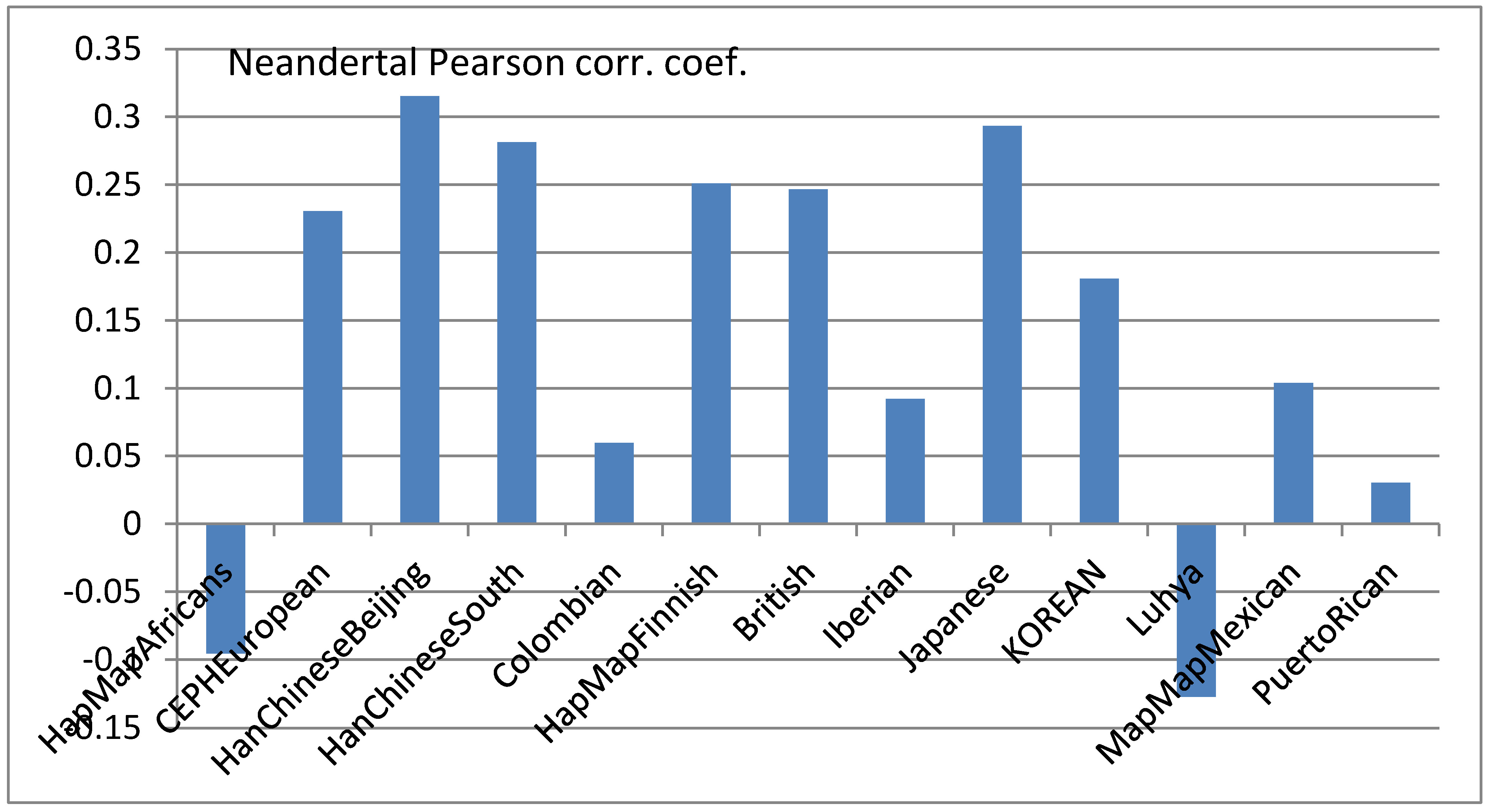 Persons correlation between the Neandertal genome and different populations. |
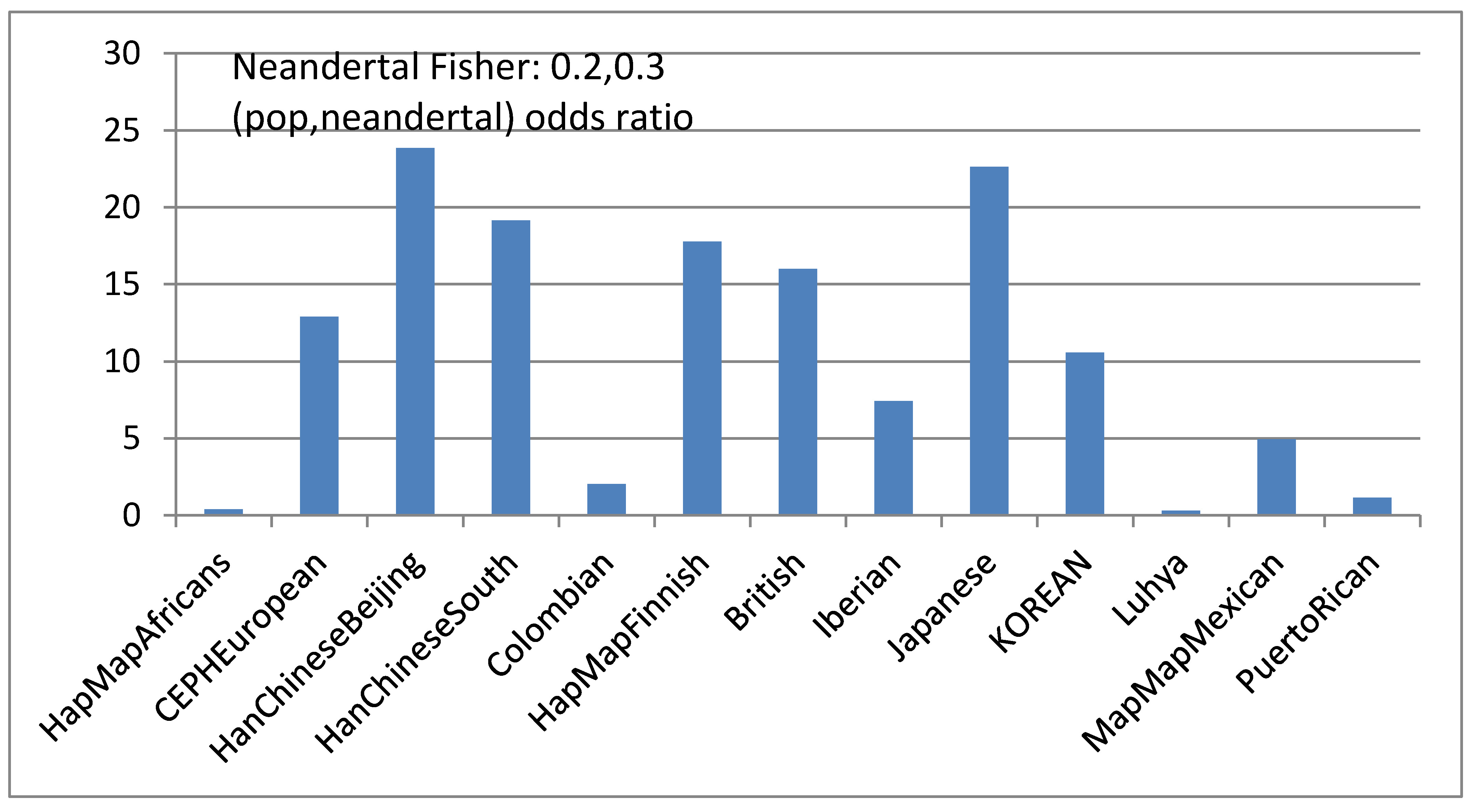 Fisher test for dependencies between the Neandertal genome and different populations. |